原文链接:Zero-Shot Learning Through Cross-Modal Transfer
摘要
本文主要的贡献在于将传统的零次学习拓展到了广义零次学习(GZSL),即在测试阶段所面对的数据可能属于已见类别或未见类别,而不是仅仅属于未见类别,是GZSL的提出文章。
本文实现这一拓展是通过,将文章中的单词的分布视为语意空间来理解目标“看起来张啥样”其实就是基于词向量的方法,然后将输入图片嵌入到词向量空间中,并区分已见和未见类别。本文提供了两种区分策略,分别倾向于保持较高的未见类别和已见类别的正确性。
介绍
现实生活中,解决这一类问题是很普遍且重要的,由于对于图片信息的标记的成本是非常高的,于是在网络实际使用的过程中,能够识别已知类别的同时,能够仅根据描述识别到未知类别可以节省很多标记的成本,且能够一定程度上实现出现新类别后的持续学习和使用。
本文的最大的贡献在于能够同时在测试阶段接受已见与未见的类别并且能够将至区分,而这样的功能的实现是基于以下两个主要的观点。
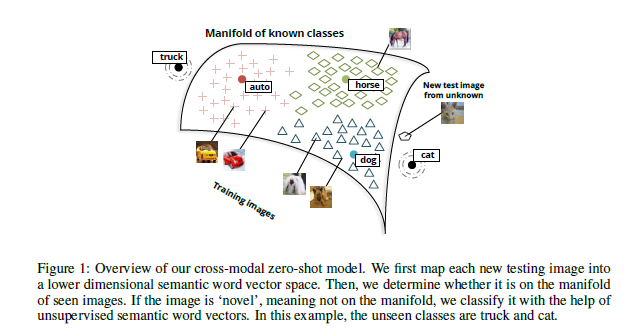
上图是模型的图解。流程为学习词向量;学习输入图片的嵌入函数;由于直接的测试会更倾向于已见类别,所以对于测试阶段的输入,我们先进行一个新鲜度检测(novelty detection);根据结果为已见还是未见执行普通分类或者零次学习分类。对于新鲜度检测的方法,本文提出了两种,均基于outlier detection method,分别更优先保护未见和已见类别的分类准确度。
相关工作
ZSL
OSL
知识和视觉属性的转移
更多的设计当我们使用属性而不是词向量来做ZSL的中间层的时候。
领域适应
是现在ZSL的一个主要问题之一,形象化举例:训练时的“有尾巴”属性基于马而训练时面对的是兔子,虽然都是尾巴但是区别很大。使用词向量而不是属性并不代表不会面对这样的问题,因为这个问题的本质是训练时学习到的特征和知识等能不能完全有效的移植到测试时面对的输入
多种形式的信息的嵌入
指不同形式的信息(本文中为图片和文字)嵌入到一个共同的空间中的问题。
单词和图片的特征描述
对于单词:使用词向量。词向量是通过对每一个单词使用一个向量来描述,以保持单词之间的语意关系,而主要的技巧在于这个向量的构建。大多数情况下这个向量的构建信息是取自文章中共同出现的单词。
除非其他的说明,本文中的词向量是使用的参考文献中的50维词向量。
对于图像,本文使用参考文献中的无监督的方法提取的I个特征,组成一个I维向量来描述。
将图像映射到语意空间
问题设定如图:

该空间中的分布情况如下图:
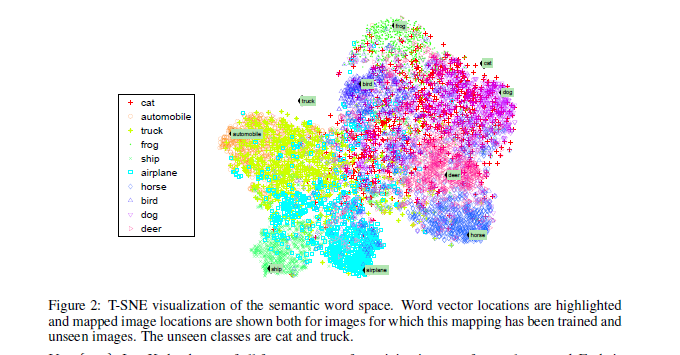
我们可以发现大部分的已见类别的图片都紧紧的分布在他们各自的类别的词向量附近,而未见类别(这里是 cat 和 truck)并不靠近任何词向量。(不过可以发现它们和它们相近类别的词向量靠的相对进一些)
ZSL模型
本章中将先给出一个模型的总览,然后具体介绍各个部分。
总体来讲,本文要完成的工作是得到条件概率p(y|x),对所有已见和未见的类别y。为了达到这一目的,本文使用的是这些图片x连接到的语意向量f(语意空间F内)。由于传统的分类模型并不会处理未见类别,所以本文引入了新鲜度这一个二元的随机变量V来表示输入的图片x是已见类别的实例还是未见类别的实例。
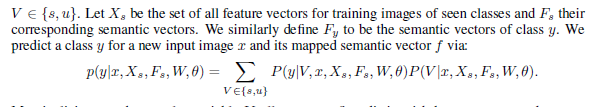
随后便可以分别处理两类图片了:对于已见类别使用 state-of-the-art 的 softmax 分类器;对于未见类别可以使用简单的高斯鉴别器作为分类器
新鲜度检测的策略
本文考虑了两种鉴别方法,均是基于 outlier 检测的方法发展的,且都是在训练的图像的流型结构上计算的。
-
第一个方法相对自由,它仅仅在每个图像的边缘上使用为阀值,而这个边缘是根据等距、类特定(class-specific)的高斯进行划分,且由已见类别的代表点计算得到。具体实现过程如下图:

这种方法的主要问题是它并没有给离线样例一个真正的可能性,而直接计算分配的方法也会出问题,因为可以发现,许多未见类别的例子并不是真正的 outlier
-
因此本文改进了参考文献中的方法,不过沿用了其中的参数$k = 20$, $\lambda = 3$分别为kNN的参数和一个可以大致看作标准差的乘数的参数(它越大,代表一个点需要距离均值更远才会被视为outlier)。具体公式如下:

分类方法
如上所说,对于已见类别,可以采取现有分类方法,本文采用的是一个softmax分类器直接对原来的I维特征进行分类;而对于未见类别,本文对每一个词向量假设了一个等距的高斯分布来提供相似度进行分类。