原文链接:Generalized Zero- and Few-Shot Learning via Aligned Variational Autoencoders
Generalized Zero- and Few-Shot Learning via Aligned Variational Autoencoders
摘要
许多的泛化零示例学习的方法集中在研究特征空间和类别嵌入空间的跨模态映射上,另一种常用方法是通过生成图片或图片的特征来强化数据集,然而前者会漏掉细粒度的细节,后者又要求学习一个与类别嵌入向量有关的映射。在本文中,作者又进一步提出了一个新的模型,通过一个有模态特异性(modality-specific)的对齐变分自动编码器学习一个图片特征和类别嵌入共享的隐藏空间。这为我们提供了我们需要的关于图像和类别在隐藏的特征上的区分性高的信息,在此之上我们训练了一个softmax分类器。本文方法的关键是作者通过调整从图片和侧面信息(应该就是指类别的嵌入向量,包括属性向量或词向量等)中学习到的分布来构建包括与unseen类别有关的基本多模态信息的隐藏特征。
介绍
GZSL是一个有挑战性的工作,尤其是对于不平衡的大数据集例如ImageNet。由于unseen类别的图片在训练阶段并不可用,所以通常需要通过一些反映类别间关系的侧面信息来实现知识从seen类别到unseen类别的迁移,例如类别嵌入。许多的泛化零示例学习的方法集中在研究特征空间和类别嵌入空间的跨模态映射上,另一种常用方法是通过生成图片或图片的特征来强化数据集。然而由于在合成图片中的细节损失程度,从他们中提取出来的CNN特征往往不能提高分类正确率。为了解决这个问题,有人提出了使用conditional WGAN。但尽管基于GAN的方法能够提高GZSL的表现, 他们所使用的损失函数在训练过程中均有较大的不稳定性。(毕竟是两个网络的协同训练,总归会出现这样的问题)于是,最近conditional VAE被用来取代GAN以解决上述问题。(VAE难道不是更初级的方法吗emm)由于GZSL本质上是一个多模态学习的任务,有人提出将两种模态都转换到自动编码器的隐藏空间中,并通过最小化最大平均差异(MMD)来匹配相应的分布。学习这样一个跨模态的嵌入是对可能的需要多模态的下游任务,例如视觉问答,有益处的。
在本文中,作者训练了VAE来对来自不同模态的特征进行编码和解码,例如图片和类别属性,并用学习到的隐藏特征来训练一个GZSL的分类器。本文中的隐藏代表(这里用的是latent representations,不知道有什么不同)是通过对它们的参数化的分布进行匹配以及通过实施一个跨模态的重建标准进行对齐。因此,通过明确的在隐藏特征和使用不同模态学习到的隐藏特征的分布均实施对齐,VAE可以将知识转移到unseen类别的同事不忘记seen类别。
本文的主要贡献有:1. 提出了CADA-VAE模型;2. 在传统的ZSL数据库下进行了实验并在GZSL和few-shot learning两个任务上打破了现有最高水平,同时我们也展示了该模型可以简单的拓展到模态数超过二的情况;3. 在大规模的数据库,如ImageNet下也突破了现有最高水平。
相关工作
-
GZSL和Few-Shot Learning
-
GZSL的数据生成模型
-
跨模态嵌入模型:ReViSE;SMAE等
-
生成模型中的交叉重建
交叉重建在领域适应(domain adaptation)中被普遍应用。与CycleGAN等直接在领域之间进行数据的生成,使用隐藏空间的模型一般会使用交叉重建来在他们的直接隐藏代表中抓住两个领域所共有的信息。
CADA-VAE模型
本文提出的模型主要的一点创新是,它并不生成图像或图像特征,而是生成低维度的隐藏特征并在保证稳定的训练的同时达到了顶尖的效果。所以,本文方法的关键就是VAE的隐藏空间的选择、重建及交叉重建的标准以在低维度使足以区分类别的信息得以保留、明确的分布对齐以更好的提取与领域无关的代表。
背景
-
GZSL任务的定义如下:
其中,$S={(x,y,c(y))|x\in X,y\in Y^S,c(y)\in C}$是训练样例集合,其中$x$是图片的特征,$y$是类别标签,$c(y)$是类别$y$的类别嵌入向量。同时,一个附加训练集合$U={(u,c(u))|u\in Y^U,c(u)\in C}$也在训练阶段被使用,其中$u$代表unseen类别标签,$Y^U$和$Y^S$不相交。另外,$C(U)={c(u_1),…,c(u_L)}$代表所有的unseen类别的类别嵌入向量的集合。我们的任务是学习一个分类器$f_{GZSL}:\ X\rightarrow Y^U\cup Y^S$。
-
VAE
本文的模型的基本建造模块是VAE。变分推断旨在找到潜在变量的真实条件概率分布,$p_\phi(z|x)$。由于这个分布的互动性,它可以通过找到和它最近的代理后验
分布(proxy posterior,$q_\theta(z|x)$)来估计,而这个代理后验可以通过最小化(确定不是最大化嘛?????)其距离的变分下界限制来找到。其中,第一项是重建误差,第二项是$q(z|x)$和$p(z)$之间的unpacked Kullback-Leibler divergence。先验分布$p(z)$的通常选择是一个标准的高斯分布。编码器给出$\mu$和$\Sigma$的预测使$q_\phi(z|x)=\mathcal{N}(\mu,\Sigma)$,随后一个隐藏向量$z$被通过重新参数化的方法(reparametrization trick)生成。
交叉且分布对齐的VAE
本文的模型的目标是在一个$M$个数据模态的公共空间中学习代表,所以本文的模型包括$M$个编码器(每个输入模态对应一个)来将输入映射到这个共同的空间。为了减少信息的损失,最初的输入数据必须能通过解码网络进行重建。于是本文模型的基础的VAE损失就是这$M$个VAE损失的和:
特别地,在基础GZSL任务中,$M=2, x^{(1)}\in X, x^{(2)}\in C(Y^S)$。然而,想要让各输入模态的编码器对于相对应的输入学到相似的代表需要额外的正则项。因此,本文的模型将隐藏的分布明确的进行对齐并且实施一个交叉重建规则,分别称为交叉对齐(Cross-Alignment, CA)和分布对齐(Distribution-Alignment, DA)。相关示意图如下:
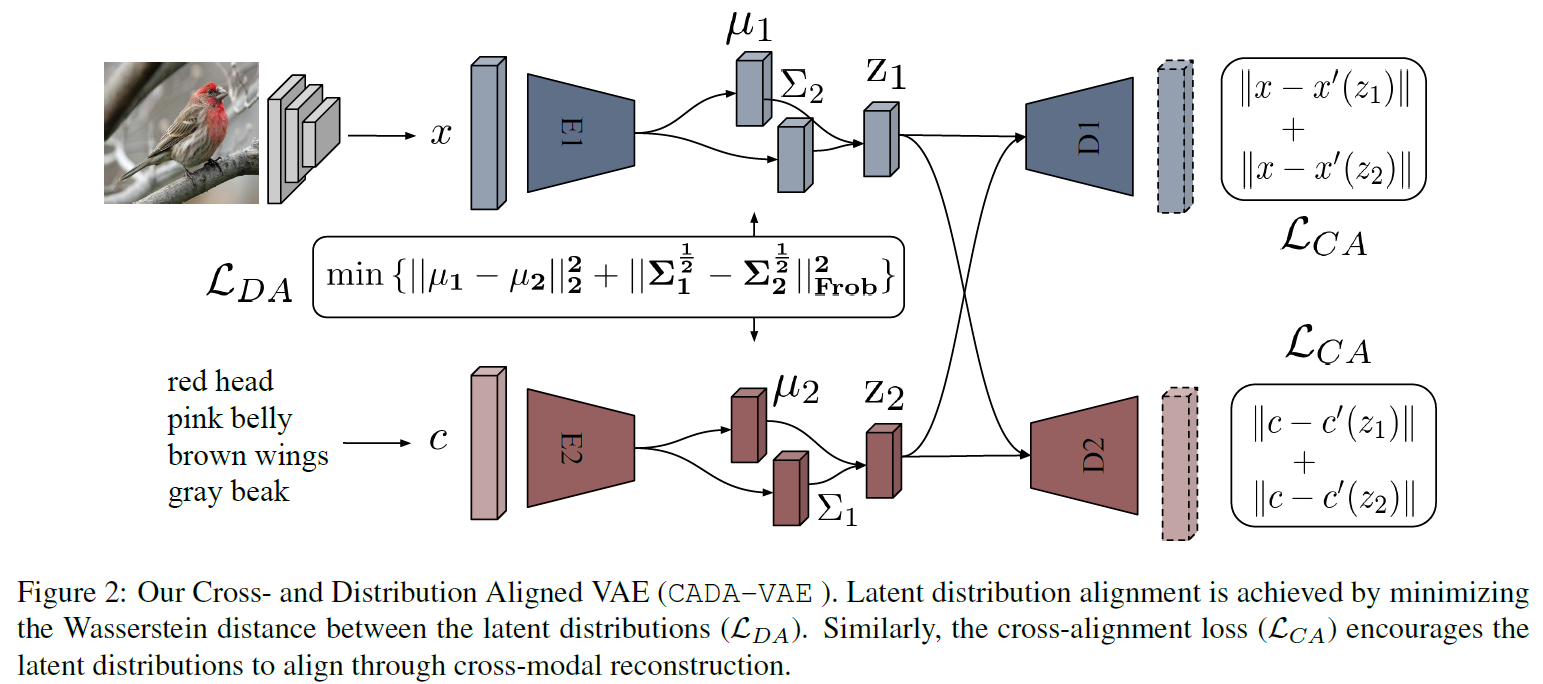
-
CA:
在这里,重建是通过对同类别其他模态的输入生成的隐藏的编码进行解码得到。因此,各个模态的解码器都在用其他模态得出的隐藏向量上进行训练,这个交叉重建损失如下:
-
DA:
生成的图像和类别代表也可以通过最小化它们之间的距离来匹配。对此,本文通过最小化这两个隐藏的多变量高斯分布之间的瓦瑟斯坦距离(Wasserstein distance)来实现。在$i$和$j$之间的2-Wasserstein距离的解析解为:
(确定这个公式没有问题嘛???)又因为编码器预测的协方差矩阵是对角矩阵,即可交换的,所以这个距离可以被化简为:于是DA损失函数如下:
-
CADA-VAE损失函数:
-
应用细节:
所有的编码器和解码器都是带有一个隐藏层的多层感知器,更多的隐藏层反而会使效果变差因为特征和属性已经是非常高等级的代表了。
实验
另外,一些我的思考
由于看到后来忘记了他摘要里面写的用softmax做分类,经过对代码的又再次确认了这一点:他并不是一个端对端的训练,在训练完整个的VAE后,还有再在$z$的基础上训练一个简单的linear+softmax的分类层,用于最终的分类。
于是我又开始困惑这样的网络为何会work,怎么避免或减小其中的泛化问题的,突然想起来他是在“生成网络解决泛化问题”的基础上改进的,所以本质上也是一个用生成的方法解决泛化问题的,进而想起他在训练分类器的时候实际上是有unseen类别的样例的,只不过这个样例仅仅只有通过类别属性生成的$z$这一个分布,但是也会在很大程度上减轻泛化带来的bias。
于是整个想法中最重要的,最基本的假设就变成了:在seen类别上,两个VAE得到的隐藏向量能够非常接近,于是对于unseen类别这样的性质可以保持。所以这样的假设究竟是不是太强,能否在大多数或者说实际的情况下保持,就成了这个方法是否make sense的主要问题。
另外,考虑到这个隐藏层和属性层之间的关系,可以发现,在很大程度上,两者是同质的,也就是说这两者的本质都是用一个向量(或分布)来表示一个类别。甚至从本文中可以看出这个隐藏空间的维度还比属性空间小。所以上述的假设实际在本质上和我们一般的ZSL中假设的——我们另seen类别的嵌入靠近对应类别属性或词向量则unseen类别也能保持这样的性质——本质上是一样的。所以这样的假设应该并不比一般ZSL的假设强,所以可以认为是合理的。
从另一个角度想,我们显然知道,在属性空间上直接使用一个linear+softmax层进行分类(即对每个图片,得到特征后直接映射到属性层或传统意义上的公共映射层,不进行大多数方法使用的最近邻分类,而是使用linear+softmax进行分类),在直观感觉上是不能工作的,因为在意义上是不符合的。但通过了VAE,既是添加了一个限制,同时也是将原来属性或词向量的硬性意义模糊化,从而可以理解这样做确实可以work。