原文链接:f-VAEGAN-D2: A Feature Generating Framework for Any-Shot Learning
f-VAEGAN-D2: A Feature Generating Framework for Any-Shot Learning
摘要
当有标注的图片很稀少时,现行的数据加强方法都无法利用大量的未标注图片信息。作者在本文中针对不限示例学习(包括零示例学习和小样本学习)的问题提出了一种统一的解决方案,并且可以在inductive和transductive两种设定下工作。他们设计了一种条件生成网络可以结合VAE和GANs的有点,并通过一个非条件限制的分辨器学习一个未标注图片的边际特征分布。通过实验,作者证明他们提出的网络能够学习到高度区别性(只用区别性来形容显然是不准确的,至少还应该是类别间可转移性的知识)的特征并且是可解释的。
引入
针对不可能对每一个物体都获取足量的标注图片这一问题,现有的新兴起的生成方法普遍都存在缺陷。首先,他们基于简单的生成网络,并不能很好的学习到复杂的数据分布;其次,许多情况下,他们都没有真正的生成被推广到那些没有足够标注图片的类别中;最后,虽然真实特征加生成特征的训练能够达到最好水平,但是生成特征并不具有可解释性。
本文主要的工作是提出了一个新的模型用于生成任何类别的视觉特征,当标注图片可获取时,利用它们进行训练,并推广到标注图片不可获取的类别中。之前的工作大都采用了GANs完成这项任务,但是他们基本都具有model collapse的问题;此外,VAE方法更加的稳定,但VAE仅仅是在优化下界,而不是相似度本身。而作者的工作将两者的有点结合起来,提出了一个通过类别嵌入(特征向量或词向量)生成CNN特征的条件生成网络f-VAEGAN-D2。另外,由于网络有不被条件限制的分辨器来分辨真实图片和合成图片,我们的未标记图片也能不带任何条件的被利用到了。他们的网络既提升了性能,又具有可解释性。
本文的模型主要由一个条件编码器、一个共享的条件解码器/生成器、一个条件分辨器和一个无条件限制的分辨器组成。前三者用于在给定一个类别嵌入的情况下通过VAE和WGAN的损失函数训练得到一个CNN特征的条件分布,最后一个部分用于学习一个新类别中未标记图片的CNN特征的边际分布。训练完成后,网络用来合成用于加强交叉熵分类器的区别性视觉特征。
相关工作
Zero-Shot Learning
Few-Shot Learning
Generative model
模型
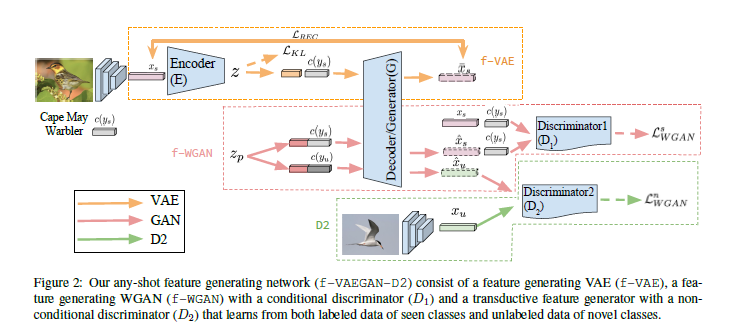
本文的模型在实际的应用中只是作为一个数据增强的措施,用于提高分类器的分类效果,在本文中,作者假设最终的分类器是简单的线性softmax分类器
基线
在特征生成网络(f-WGAN)中,生成器$G(z,c)$通过随机噪声($z_p$)和条件($c$)生成一个在输入特征空间$\mathcal{X}$中的特征$\hat{x}$,然后分辨器$D(x,c)$将输入的特征$x$和条件$c$作为一对输入,然后输出一个实数。相应损失函数为:
其中,$\tilde{x}=G(z,c)$是生成的特征,$\hat{x}=\alpha x+(1-\alpha)\tilde{x},\ \alpha\sim U(0,1)$以及$\lambda$是一个惩罚参数。
在特征生成VAE(f-VAE)中,网络包含一个编码器$E(x,c)$用于将输入特征$x$和一个条件$c$编码成一个隐藏变量$z$,和一个解码器$Dec(z,c)$用于从隐藏的$z$和条件$c$中重建输入$x$。相应的损失函数为:
其中,条件分布$q(z|x,c)$是由$E(x,c)$模型化出来的,$p(z|c)$假定为$\mathcal{N}(0,1)$,$KL$为KL散度,$p(x|z,c)=Dec(z,c)$
本文的模型:f-VAEGAN-D2
有工作已经证明,VAE和GAN堆叠是可以提高表现的。本文假设VAE和GAN学习到的信息也是有一定程度互补的,而当目标数据遵从一个复杂的多模型分布且不同的损失函数只能抓取到数据不同的模式的时候这个假设成立。
为了结合VAE和GAN,作者引入一个生成器$E(x,c)$,一个分辨器$D_1$,同时让生成器$G(z,c)$和解码器$Dec(z,c)$共享参数,并且优化如下损失函数:
其中,上标$s$代表这个损失函数是针对已见类别的数据对的,$\gamma$是用于控制两种损失函数权重的超参数。
另外,当新类别的未标记数据可获取时,作者继续为网络引入了一个无条件限制的分辨器$D_2$来区别新类别中的真实特征和生成特征。这样$D_2$就能学习到新类别中的流形结构。本文用如下的损失函数来训练$D_2$:
由于使用到了类别嵌入,而类别嵌入中应该含有类别间能够共享的性质,所以作者期望生成的CNN特征是有类别间的可转移性的,但是这很大程度上依赖于类别嵌入的质量,而且会有领域位移的问题。而这里的$D_2$便被寄希望于学习到CNN特征的边际分布,并为新类别生成可转移的CNN特征提供有用的帮助。
于是,最终的目标函数为:
实验
一些自己的想法
同一个问题的多种解决方法混用,但是不能是简单的叠加。
还是有很多的行文问题,比如WGAN的损失函数的符号解析一直有问题,损失函数和图片上写的并不一致,且全文没有解释$\mathcal{L}_{REC}$是啥以及咋实现的。
整体思路并不是很有新意,讲到底并不是对他应用的所有问题的最核心的部分都有创新,尤其是强行能用到inductive设定下。也许这就是他们铺开应用面并且强调普适性的原因,来弥补方法上的创新型不足。
但问题是,对于inductive的设定,没有看到能让新类别分类成功性有任何特别的提高的地方,但是还是有提升。
如果认为是两个模型的叠加让获取的特征更好了而带来的整体提高,并没有针对性解决seen bias的话,那么对比inductive设定的提升和transductive设定的提升,他的$D_2$是否由真的带来了很大的提高呢?