原文链接:RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation (2016)
摘要
为了解决在下采样时造成的分辨率的显著的损失,本文采用了长程的residual connections。另外本文引入了chained residual pooling,它可以有效的抓住rich background context
Introduction
DeepLab的限制:需要在大量的细节特征图(通常很大)上进行convolution,computational expensive,且存储大量高维高分辨率的特征图需要大量GPU存储资源;少掉的卷积引入了一个对于特征的粗糙的二次取样,可能会丢失信息
高级和低级的特征都很有用,但是怎样看待和应用中间的特征,还是一个问题
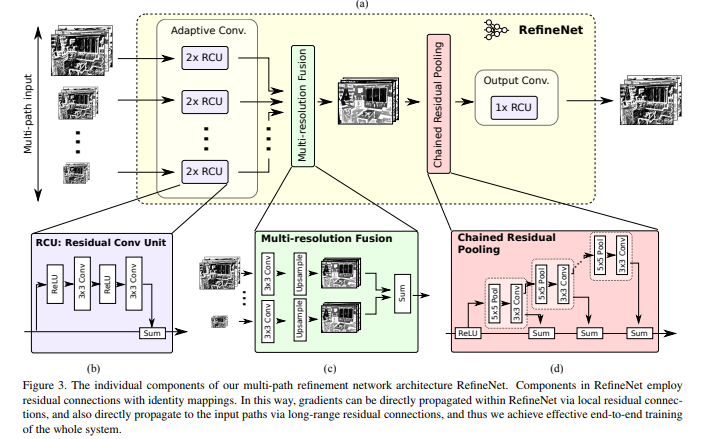
本文主要贡献: 1. 用细致的低级特征去refine低分辨率的语意特征,in a 递归 的manner,来生成高分辨率的语意特征图 2. 我们的级联的网络可以有效且高效的训练。特别的每个component都应用来residual connection,有短程和长程的backprop路径 3. 新的网络组成部分:“chained residual pooling”。他完成它的任务通过有效的对不同window大小的特征进行pooling并通过residual connection和可学习的权重将其连接(fusing)起来
本文给出的方法:block-wise
Multi-Path Refinement
关键的设计在通过长程的residual连接使梯度可以有效高效的backprop到低级的layers,从而使网络可以被end-to-end的训练
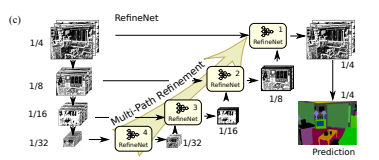
接着用双线性插值的方法还原成原图像分辨率的结果。
block的组成
Residual convolution unit -> Multi-resolution fusion (upsampling + sum) -> Chained residual pooling (旨在抓住背景context从一个大的image region,适用多个pooling block,每个含一个max pooling层(stride 为1及padding以使大小不变)和一个conv层,并且每个block都用上一个block的outputs作inputs,这样就可以实现window大小不变但感受野变大,所有block的outputs和原输入最终fuse通过summation) -> Output convolutions