DeepLabV2
摘要
本文三点主要贡献:重视conv with upsampled filters(Atrous convolution,带孔卷积);atrous spatial pyramid pooling (ASPP);fully connected Conditional Random Field (CRF)
Introduction
具体来讲,本文接下来讨论三个问题及他们的解决方法:
- 特征分辨率(featrue resolution)的下降。去除最后几个max pooling中的downsampling,并且在之后的卷积层中upsample the filter(指采取带孔卷积操作,相当于在filter上使用zero-unpooling),从而使特征图在一个更高的取样率(sampling rate)下计算。所以本文为了提高特征分辨率,采用了a combination of带孔卷积层,后跟着双线性插值,从而取代了反卷积操作。与普通卷积相比,本方法可以在保持参数个数不增加的同时增大感受野
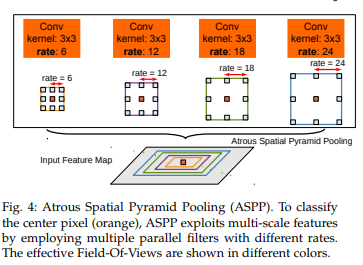
- 物体存在不同大小。灵感来自SPP,提出了ASPP
(真的仅仅是灵感来源,具体讲两者共同之处仅仅在于都是用不同大小的pooling操作来实现不同的感受野,但具体实现起来是很不一样的)(毕竟SPP是在分类中应用的而本文要解决语义分割的问题嘛) - 位置精确度的下降。一种解决方法为skip-layers(like U-Net)。本文提出了另一种方案:FCCRF
方法
带孔卷积
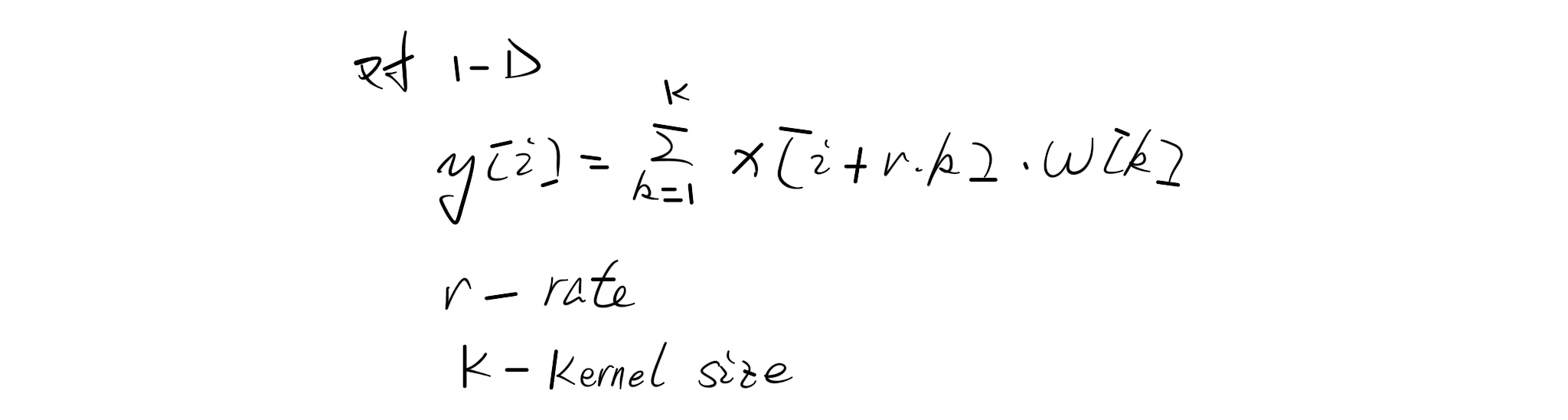
3.2 ASPP
further平行处理,并最终fuse到一起
3.3 FCCRF
short-range CRF是用来清除噪音的,并且它倾向于给空间相近的像素分配相同的标签,which和我们希望的相反
Fully-connected CRF被引入以解决这个问题。它使用能量公式:

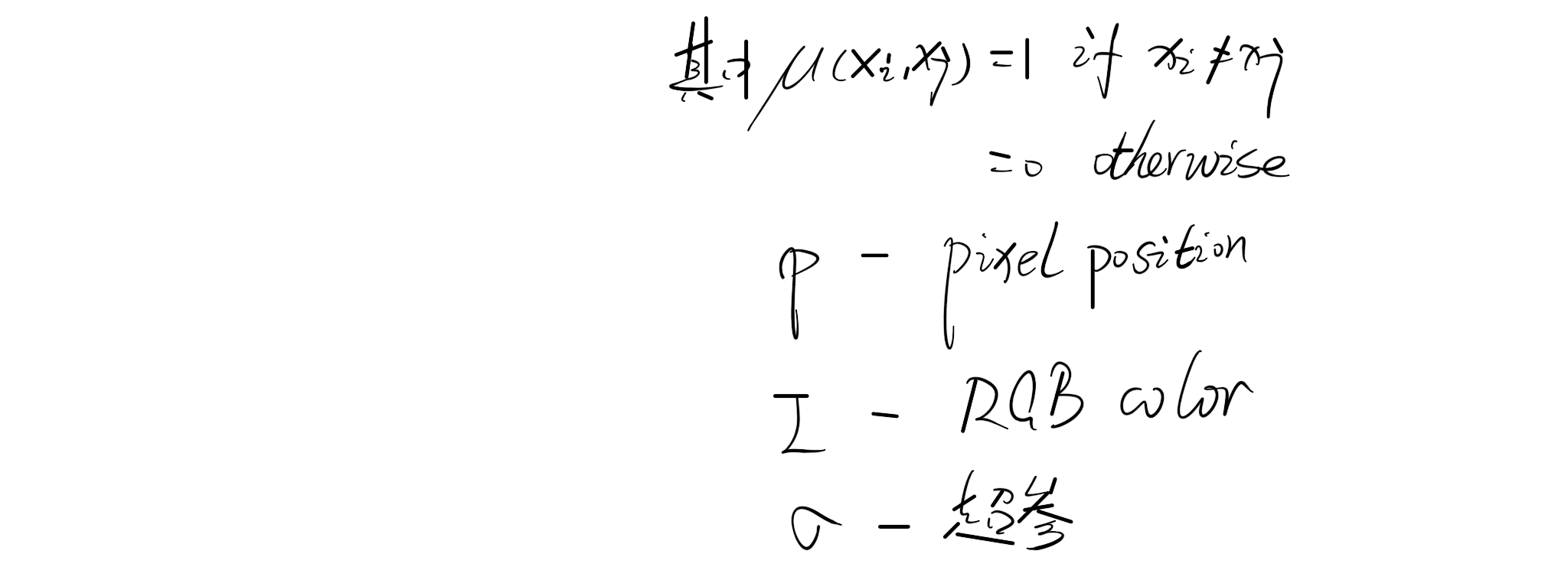
DeepLabV3
原文链接:Rethinking Atrous Convolution for Semantic Image Segmentation (2017)
可以发现相对于V2来讲,最大的不同是删去了FCCRF这个部分,可以推测这个部分并没有在最终的效果中起到很大的作用,可能更多的是一种数据的trick手段。
Introduction
对于物体的大小不一样的问题,现在有许多解决方案:
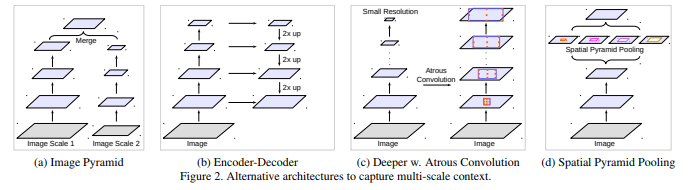
在本文所做的实验中,作者发现:
- BN很重要
- 3x3卷积with极大的rate fail to抓住大范围的信息
另外本文也分享了一些训练上的经验,包括简单但有效的bootstrapping方法来处理稀少但finely annotated objects
本文仅讨论了上述4种中的两种中带孔卷积的应用效果:c(对应层级化使用带孔卷积);d(对应平行使用带孔卷积)
方法
回顾带孔卷积
r=1为正常的非带孔的卷积 用output_stride来表示最终的resolution比输入图片的resolution小了多少倍,例如用于分类的DCNNs一般为32 如果想让他增大一倍(output_stride=16)那么本文的操作为将最后一个pooling层的stride设为1,然后后续的卷积层全部变为r=2的带孔卷积层
利用带孔卷积继续加深网络(层级化使用带孔卷积)
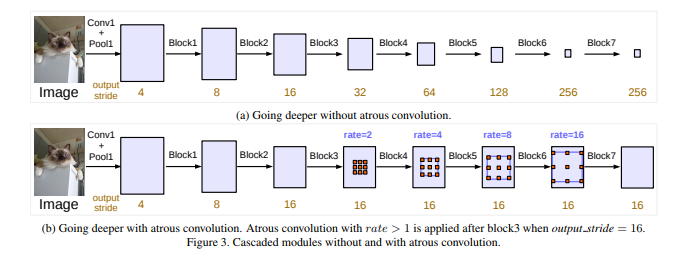
进一步的本文还使用了multi-grid方法进行优化,即对每个block,不仅仅使用一种r,而是用Multi_Grid=(r_1,r_2,r_3)x r来进行带孔卷积
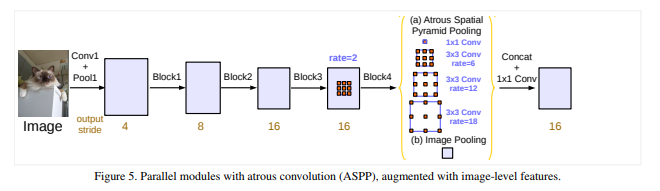
ASPP(平行使用带孔卷积)
与v2改进:引入了BN
本文发现,随着r增大,真正应用在特征上的(而不是padding的0上的)weight变的越来越少,极端情况下仅用中央的weight能够真正起作用,故而直接退化为了一个1x1的卷积层。
为了克服这种问题并且incorporate global上下文信息,本文adopt image-level特征。 具体来讲,改进后的ASPP层含有如下内容:1个1x1conv(256+BN),3个3x3conv(r=6,12,18;256+BN),1个global average pooling + 1x1conv(256+BN)+ 双线性插值。随后这些进行concatenate然后1x1conv(256+BN)。最终的final logits通过这个操作得到的map再进行1x1conv得到
DeepLabV3+
原文链接:Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation (2018)
本文主要改进为为DeepLabv3引入了一个简单但有效的decoder模型来refine分割结果,尤其是along object boundaries。本文进一步的探究来Xception(可以进一步学习)模型并且应用depthwise separable conv(可以进一步学习) to both ASPP和decoder模型
Introduction
现有主流的语义分割网络主要有两大类,一大类是DeepLav系列为代表的,另一大类便是编码-解码+跳跃链接的形式。
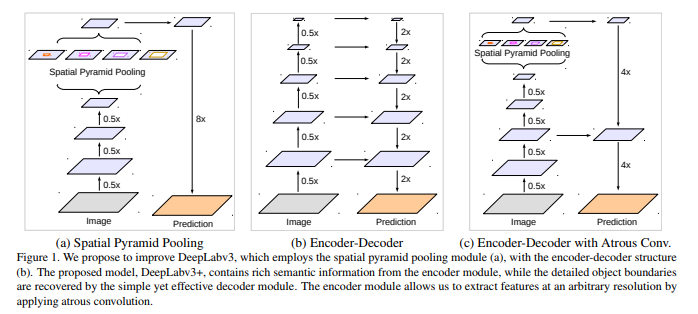
DeepLabv3受限于速度、计算力和GPU存储大小,极难做到很高的resolution(如8甚至4倍小于输入)(同时也会影响到过多的层数),而encoder-decoder就可以做到。于是本文考虑将两者的优点结合起来,对现有网络进行改进
同时本文也通过使用Xception进一步改进速度和准确率,并且在ASPP和decoder模型中应用atrous separable convolution
方法
Encoder-Decoder模型with带孔卷积
-
回顾带孔卷积
-
separable convolution:
将一个标准的conv操作分解为depthwise的conv操作followed by一个pointwise的conv(1x1conv),这样极大的减小了计算复杂度。其中depthwise conv是对输入的每一层分别进行conv操作,而pointwise conv是将这些输出进行组合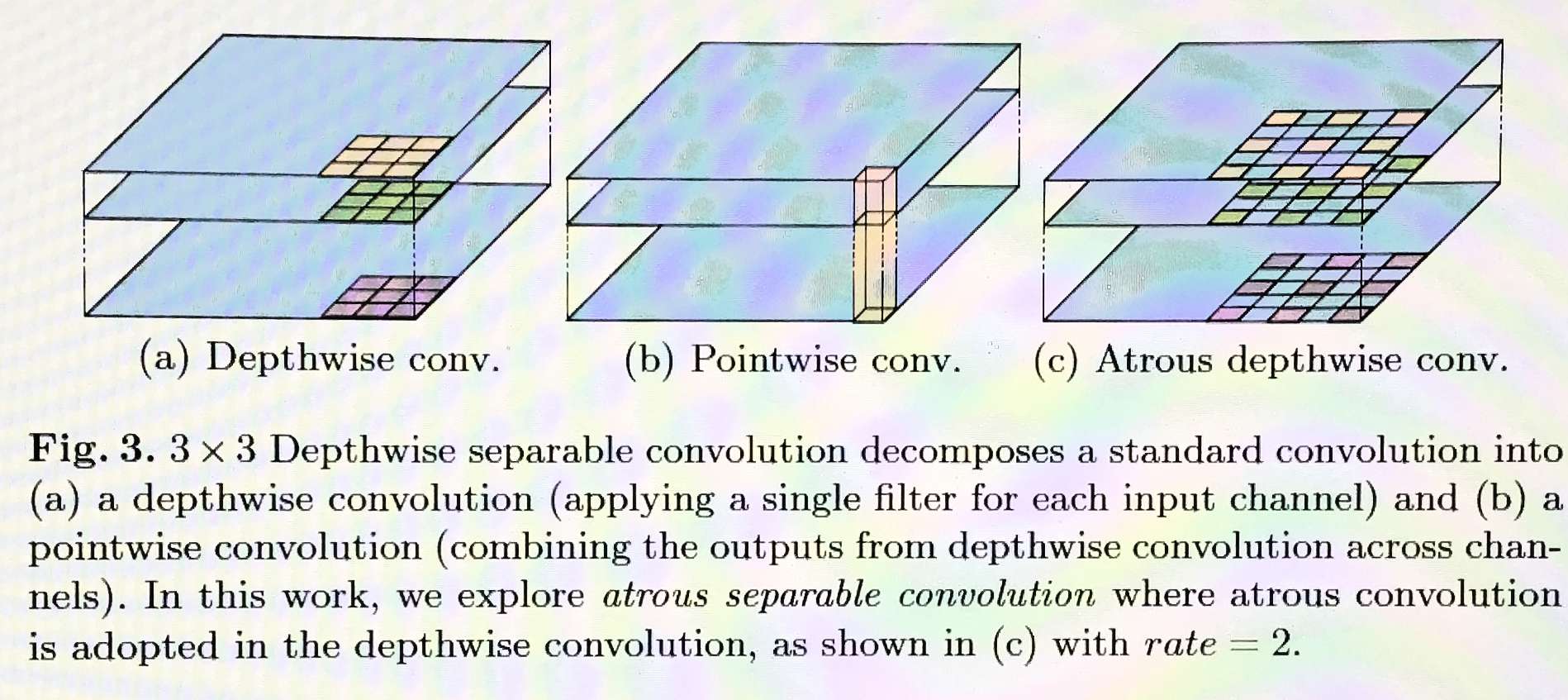
-
Deeplabv3作为Encoder
-
提出一个Decoder:
一般DeepLabv3的输出为output_stride=16,所以本文采用这个一般的比例进行decoder的构建(即decoder的upsample率为16)。但直接upsample16倍表现并不是很好,本文采用了一个简单但是有效的方法:先双线性插值upsample4倍;然后和corresponding的low-level特征进行concatenate(low-level的特征在concatenate前先使用1x1conv来减少channel数);随后我们使用一系列3x3conv来refine这些得到的特征(separable conv???);最后再用双线性插值upsample4倍本文发现output_stride=16时达到准确性和速度的最佳平衡,使用8时会较小的提高准确性,但是cost extra computation complexity
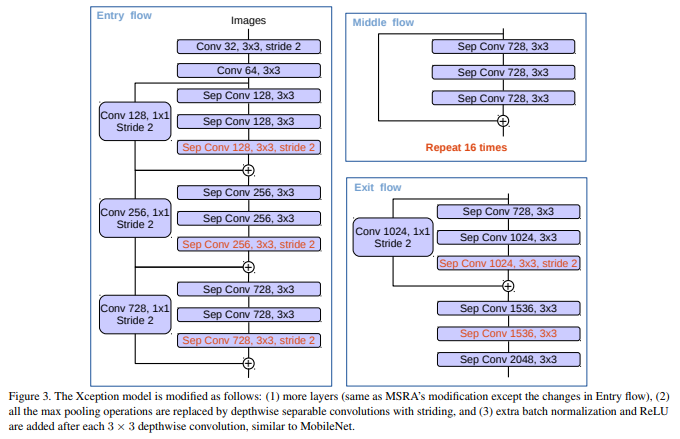
用Aligned Xception(MSRA对于Xception的调整)优化
In particular, we make a few more changes on top of MSRA’s modi cations, namely (1) deeper Xception same as in [31] except that we do not modify the entry ow network structure for fast computation and memory effciency, (2) all max pooling operations are replaced by depthwise separable convolution with striding, which enables us to apply atrous separable convolution to extract feature maps at an arbitrary resolution (another option is to extend the atrous algorithm to max pooling operations), and (3) extra batch normalization [75] and ReLU activation are added after each 3x3 depthwise convolution, similar to MobileNet design [29].